Large Language Models (LLMs) are the most talked about technology of the past 2 or so years, particularly OpenAI’s ChatGPT which seems to get a new version come out every few months. But can you say you know how this technology works or where its limitations lie? Today we take a deep-dive on the internals of an LLM and hopefully highlight their strengths and their weaknesses, so you can make informed decisions about when and when not to use them.
But before we get into the weeds too far, let’s take a step back and consider how we think computers can process and analyse text. Obviously if you read my blog, you’re probably interested in software engineering, so you already know about strings. Unusually, then, LLMs don’t think about text as strings! They use a tokeniser to turn your text into an array of tokens (with integer IDs) and they use the same tokenizer to turn their output back into text.
What is a token?
Unfortunately there aren’t any easy starting points when it comes to understanding LLMs. We’ll start with the tokens as they’re absolutely fundamental to how LLMs process text, yet they’re often under-explained.
Tokens are, in simple terms, short pieces of words, perhaps including punctuation or other formatting characters. But that’s not a great explanation, so we should look at an example.
LLMs use a deterministic function for tokens called the tokeniser, but each model has its own one. The tokenizer takes text and slices it into predefined chunks (tokens) that the model understands. It also performs the reverse process — converting tokens back into human-readable text. The tokens are defined early on during the creation of the LLM and do not change, like a dictionary.
The easiest way to see this in action is to use an online tokeniser playground.
If we try putting in the phrase I want to know how tokenisers work. for GPT-4o, we see that it converts to the tokens ["I", " want", " to", " know", " how", " token", "isers", " work", "."].
Or, more importantly, the token IDs [40, 1682, 316, 1761, 1495, 6602, 106598, 1101, 13], since we’re about to see that These IDs allow the model to work efficiently with numbers instead of raw text, which is essential for mathematical operations like matrix transformations.
Let’s take a look at some of the things that stand out here:
- Tokens aren’t necessarily whole words, but they often are for commonly used words.
- Words after a space seem to have their own tokens, which are different from tokens without the space.
- The more commonly used the token, the lower its ID tends to be.
The tokens are used to parse training data when the LLM is created. In other words, the LLM is trained to recognise sequences of IDs that form a concept and to be able to know when those sequences should appear in text, according to other nearby patterns.
Prediction of the next token
Now that we understand tokens, let’s explore how LLMs generate responses — one token at a time. Let’s look at an example conversation to better explain this.
Let’s say you had the following question and response with ChatGPT 4o:
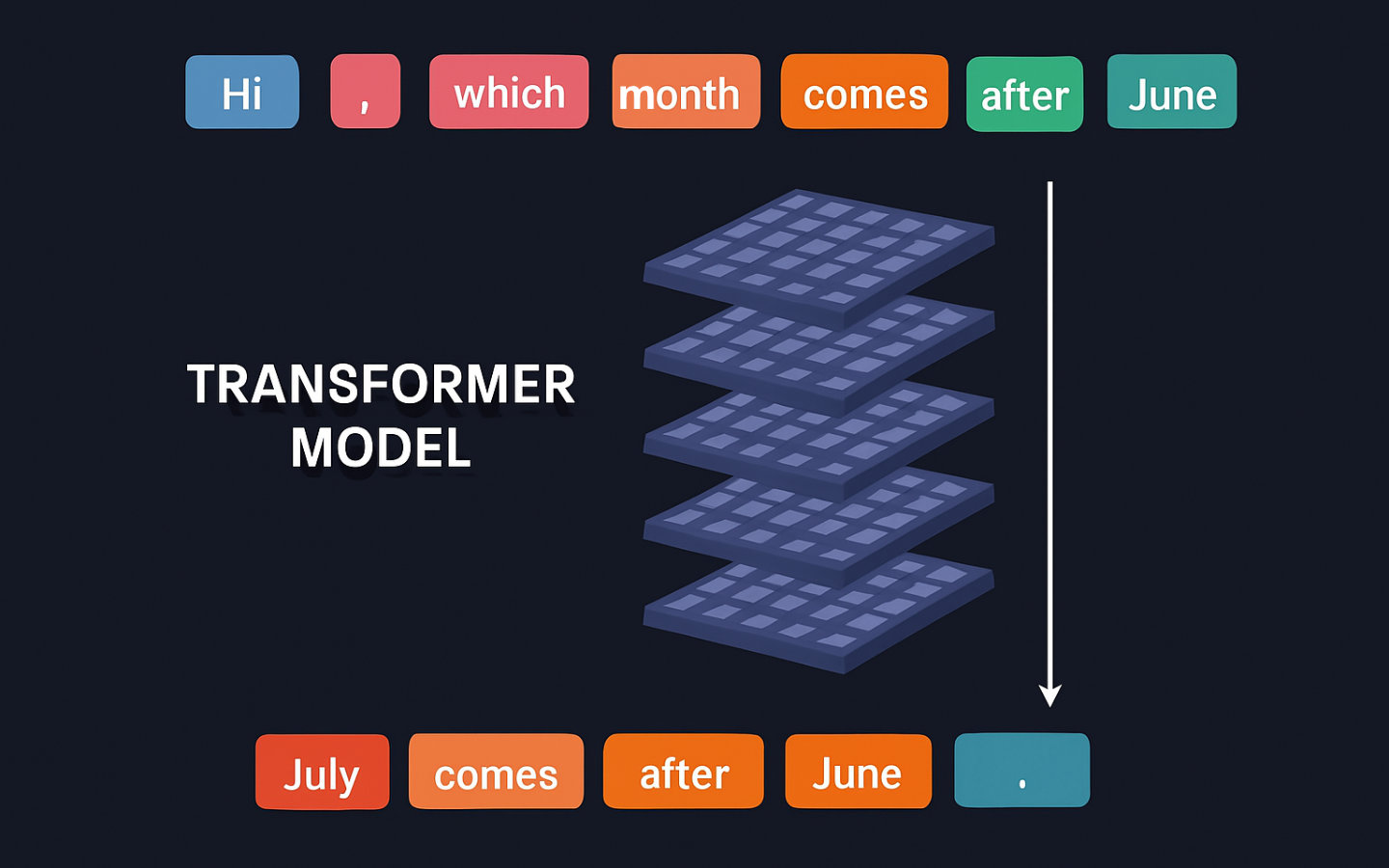
You: Hi, which month comes after June?
ChatGPT: July comes after June. 😊
Let’s take a look at the tokens for the request and the response:
["Hi", ",", " which", " month", " comes", " after", " June", "?"]
["July", " comes", " after", " June", ".", " 😊"]
You provided the first line of tokens as your request. ChatGPT 4o uses their IDs to pass them through billions of matrices which transform them into predicted next tokens. Each possible next token is assigned a probability based on how often similar sequences appeared in the training data. Once a token is selected, it’s added to the response, and the updated sequence is processed again to determine the next token. Only one token at a time gets added.
“July” was selected because, in the training data, similar sequences frequently led to that token. The model doesn’t know the correct answer — it simply predicts what is most statistically likely.
It is probably quite likely that the token for " July" with a space at the front was somewhere among the top tokens that could have been selected. This token-by-token process is what allows LLMs to generate coherent responses — but it also means they don’t truly “understand” meaning, only patterns in data.
What is remarkable is that no-one taught the LLM how to do any of this and we’re still not able to definitively explain how the responses are even remotely coherent. What we do know is that the more training data and the larger the transformer model, the more capable the LLM seems to become.
The same input doesn’t always give the same output
If you’ve ever asked ChatGPT the same question twice, you might have noticed that the responses are sometimes different. This might seem surprising — after all, the input hasn’t changed, so why should the output?
The reason is that LLMs don’t always pick the single most probable next token. Instead, they use a combination of probabilities and controlled randomness to make responses more natural and varied.
Let’s break this down:
Token probability and random selection
At each step of response generation, the model assigns probabilities to possible next tokens. For example, given the prompt:
You: What is the capital of France?
ChatGPT: The capital of France is Paris.
The LLM might calculate probabilities like this for the next token after “The capital of France is”:
- “Paris” 85%
- “Lyon” 5%
- “a city in” 3%
- “France” 2%
With the remaining 5% being made up of all other options. Instead of always selecting “Paris” (the highest probability), the model sometimes picks a different option, especially when randomness settings are higher. This prevents it from being too repetitive.
Temperature: controlling randomness
One way to control this randomness is through a setting called temperature:
Low temperature, such as 0.1, makes the model more deterministic by favoring the highest-probability token almost every time. High temperature, such as 1.0 or more, increases randomness, allowing more varied responses.
For example, with temperature set to 0.1, ChatGPT might always say The capital of France is Paris.
But with temperature = 0.8, you might get Paris is the capital of France. or The capital of France is Paris, a city known for its history and culture.
This randomness is useful for creative tasks, but for factual queries, a lower temperature is preferred to keep answers consistent.
Top-k and top-p sampling
Beyond temperature, there are other techniques that affect response variation:
- Top-k sampling: Instead of considering all possible tokens, the model only picks from the top k most likely tokens (e.g. k = 50).
- Top-p sampling (nucleus sampling): Instead of limiting by a fixed number, it selects from the smallest set of tokens whose combined probability is at least p (e.g. p = 0.9).
Both methods help balance randomness and coherence, making responses diverse but still meaningful.
The fact that LLMs don’t always generate identical responses is both a strength and a challenge. It allows for dynamic, engaging conversations, but it also means LLMs aren’t perfectly deterministic—which is important to remember when using them for critical tasks.
If you need maximum consistency, lowering temperature and enabling deterministic settings helps. But if you want creativity, keeping some randomness makes responses more interesting.
What should we be using LLMs for?
Now that we understand how LLMs work and why their responses can vary, let’s explore their best use cases. While LLMs don’t “think” like humans, they excel at recognizing patterns in text, making them incredibly useful in some key areas. Let’s look at three of them.
Content generation – just keep in mind that LLMs do not know facts, so any content that is generated must be fact checked if accuracy is critical.
- Writing blog posts, summaries and report drafts.
- Drafting emails or letters.
- Brainstorming creative ideas such as novel writing.
Coding assistance – but keep in mind that the code may be wrong or do the wrong thing. You should be responsible for any code you choose to use.
- Generating code snippets and templates.
- Explaining programming concepts with references to your actual code.
- Debugging code by analysing error messages.
Language translation and text rewriting – but turn to an expert where the outcome has serious impacts such as in law or medical situations.
- Translating between languages.
- Paraphrasing and summarising longer passages of text.
- Improving grammar and clarity, using the LLM as an editor.
When should we be looking elsewhere?
While LLMs are powerful, they aren’t the right tool for every task. There are important cases where relying on them can lead to incorrect, misleading, or even harmful results. Here are a few key situations where you should look elsewhere:
When accuracy is critical – LLMs are rooted in statistics, not verified knowledge. They should not be relied upon when making critical decisions that have real world impact.
When real-world reasoning is needed – LLMs produce convincing sounding responses, not carefully reasoned solutions. If a problem is complex, there’s a fairly good chance that the answer from an LLM will be believable, but fictional.
When ethical or sensitive topics are involved – LLMs are as biased as the data they were trained on, and the data they were trained on came from a great number of sources. If the topic requires finesse typically found in experts in a field, LLMs are unlikely to show that same level of finesse.
When security and privacy matter – especially when you are not running the LLM on hardware you control. Remember that the owner of the servers have the ability to log your conversation and to use that information, either directly, or to train a new model.
Wrapping Up
Large Language Models are an impressive achievement in artificial intelligence, capable of generating text that can feel almost human. However, as we’ve seen, they don’t truly understand the world — they predict text based on patterns from training data.
When used in the right contexts, they can be powerful tools for content creation, coding assistance, and language processing. But they are not fact-checkers, reasoning engines, or decision-makers.
LLMs are best used as assistants, not authorities. They can enhance productivity and creativity, but their outputs should always be reviewed with a critical eye — especially when accuracy, security, or ethics are at stake.
By understanding how they work and where they fail, we can use them wisely and avoid the pitfalls of blind reliance.